Understanding RAG: The Bridge Between LLMs and Your Data
Large Language Models (LLMs) like GPT-4 or Gemini are incredibly powerful, but they have two major limitations: they have a knowledge cutoff (they don't know what happened yesterday), and they don't have access to your private data (your company’s docs, your personal notes, etc.).
This is where Retrieval-Augmented Generation (RAG) comes in.
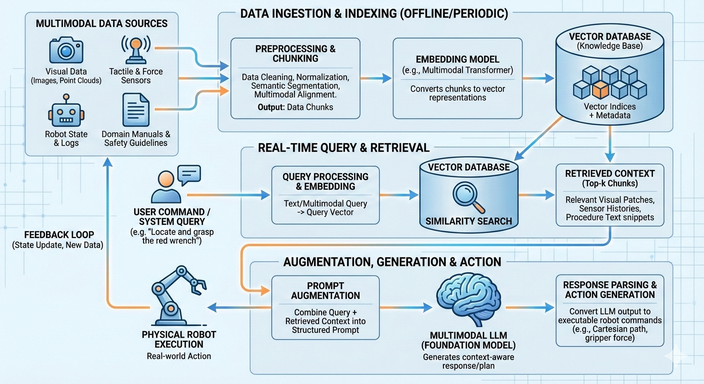
What is RAG?
Retrieval-Augmented Generation (RAG) is an architecture used to optimize the output of an LLM by referencing a trusted knowledge base outside of its training data before generating a response.
Think of it this way:
- Standard LLM: Answering a history exam based purely on memory.
- RAG-enabled LLM: Answering a history exam with an open textbook tailored specifically to the subject.
How RAG Works: A Step-by-Step Breakdown
The RAG process can be broken down into two main phases: the Data Preparation phase and the Inference (Retrieval & Generation) phase.
1. Data Preparation (The Indexing Phase)
Before you can ask questions, you have to make your data "readable" for the AI.
- Loading: Importing documents (PDFs, HTML, Markdown).
- Chunking: Breaking long documents into smaller, manageable pieces.
- Embedding: Converting these text chunks into numerical vectors using an embedding model.
- Vector Store: Storing these vectors in a specialized database (like Pinecone, Milvus, or Weaviate).
2. The Retrieval & Generation Loop
When a user asks a question, the following happens in milliseconds:
- Query Transformation: The user's question is converted into a vector.
- Retrieval: The system searches the Vector Store for the "chunks" of text that are mathematically most similar to the question.
- Augmentation: The system combines the original user question with the retrieved chunks into a single prompt.
- Generation: The LLM reads the provided context and answers the question accurately.
Why Use RAG Instead of Fine-Tuning?
A common question is: "Why not just fine-tune the model on my data?" While fine-tuning is great for teaching a model a specific style or vocabulary, RAG is usually superior for facts.
| Feature | RAG | Fine-Tuning |
|---|---|---|
| Knowledge Update | Instant (just add a new doc) | Slow (requires retraining) |
| Transparency | High (can cite sources) | Low (black box) |
| Cost | Low | High (GPU intensive) |
| Hallucination | Significantly Reduced | Still Possible |
The Benefits of RAG
- Accuracy: It grounds the model in factual, up-to-date information.
- Source Attribution: RAG systems can provide citations, allowing users to verify where the information came from.
- Data Privacy: You don't need to send your entire dataset to a model provider for training; you only send the relevant snippets during the prompt.
Conclusion
RAG is the gold standard for building AI applications that need to be reliable, factual, and specialized. By bridging the gap between a model's reasoning capabilities and your specific data, you turn a general-purpose AI into a powerful, domain-specific expert.